What is Chatbot
A basic chat messenger is a very well known tool used both in personal and enterprise applications from decades. We have been using text messages to instantly reach people for several years and It’s one of the most convenient and economical tools available in the world of communication.
Traditional chat applications are being used by businesses to connect with their customers. A human agent with experience in the domain helps the customers through chatting and it is helping the businesses in revenue growth, accelerate sales, and improve support efficiency.
A Chatbot is a conversational agent that is programmed to communicate with users through an intelligent conversation using natural language. A smart chatbot can chat with a human and answers different queries ranging from answering a simple customer query to a product recommendation on an e-commerce platform.
The problem
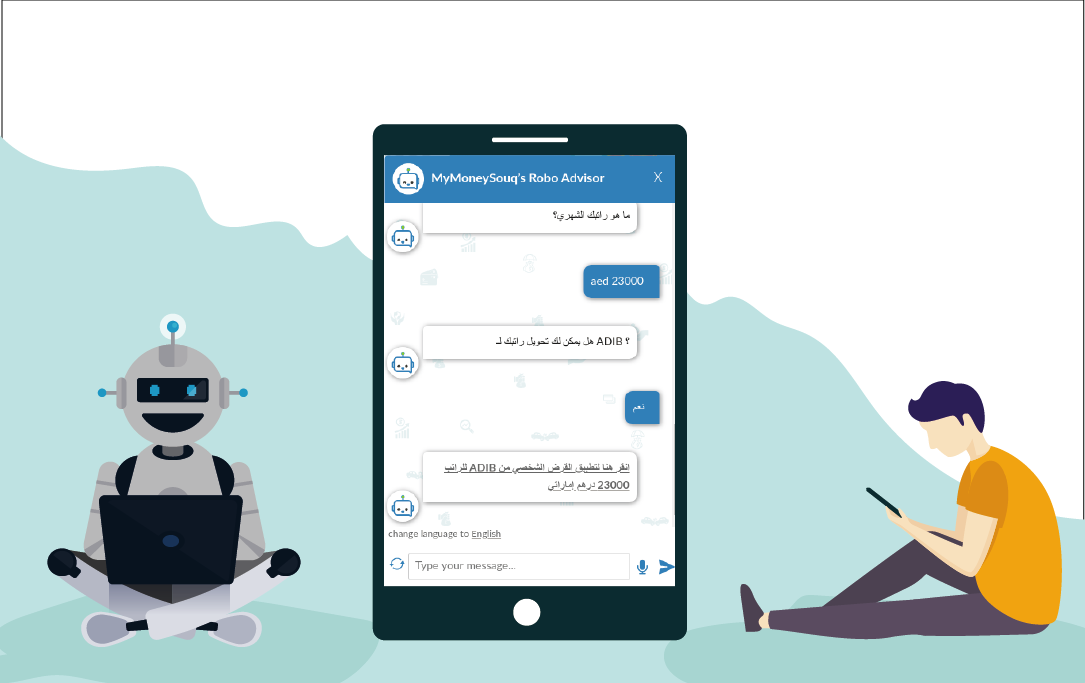
We built a personal finance marketplace called MyMoneySouq to help online users choose the right financial product in the UAE. MyMoneySouq has become one of the top players in the region in the last few years.
People who visit our platform have many queries while searching for the right financial products and often end up browsing many products on our platform.
Our Solution
At MyMoneySouq, we want to create a unique conversational experience for our visitors. A Chatbot can help our website visitors not just in getting answers on personal finance topics but also to make personalized product recommendations.
We are living in the age where machines are competing with humans in intelligence and the rise of AI is making it harder to discern bots from humans. We have used the latest developments in the areas of NLP, deep learning and Speech-to-text technologies to build one of the best conversational Chatbot in the Industry.
“In the rest of the article, we describe how a smart chatbot can be built with ARABIC language as the preferred language. The intention is to share knowledge and learnings so that it can be reused for the greater good of the community”
Architecture of a Smart Chatbot
A smart chatbot can be built with NLP and machine learning framework to process text messages, predicting the user intent and provide the best possible answer from it’s knowledge base.
A user message is processed by a natural language processing tool for intent classification, response retrieval and entity extraction.
Natural language understanding mechanism understands user messages and the core framework decides what action has to be taken for a user query and also holds the context of user conversion.
To understand how the Chatbot works is necessary to know the basic flow of the conversation: the user gives an input, the agent parses this input running a NLP task and the agent gives an answer to the user based on the entity extracted from the conversation.
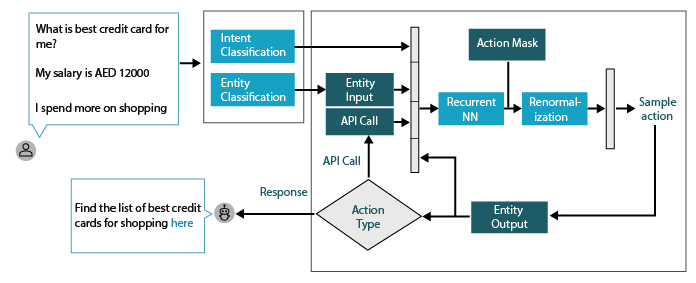
The Chatbot system is a sequence of components that will be executed sequentially on the user input. There are severals types of built-in components:
- Model initializer loads pre-trained word vectors in a given language, such as spaCy or MITIE.
- Tokenizer is used to split the input text into words.
- Featurizer transforms the tokens as well as some of their properties into features that can be used by machine learning algorithms.
- Entities are keywords used to identify and extract useful data from inputs. While intents allow the Chatbot to understand the motivation behind a particular user input, entities are used to pick out specific pieces of information that your user mention including entity values linked to the entities
- Named entity recogniser extracts entities (e.g. product, dates, etc.) from the input.
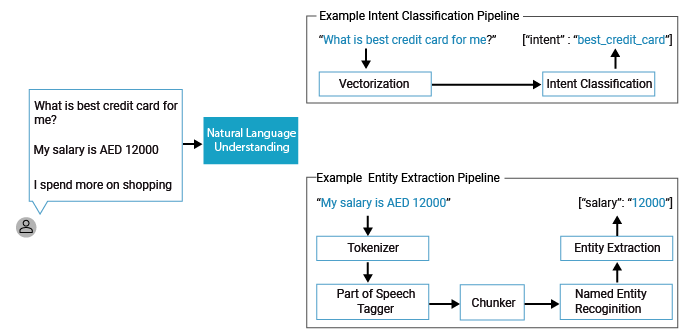
- Intent maps user input to responses. It can be viewed as one dialog turn within the conversation. In each intent, are defined examples of user utterances, entities and how to respond.
- Intent classifier extracts an intent (e.g. apply for credit card) from the input.
- Interpreter extracts intents, entities and others structured information
- Tracker is used to store the conversation history in memory, it maintains conversation state.
- Policy decides what action to take at every step in a dialogue, the action depends on the tracker input that holds the context of the conversation.
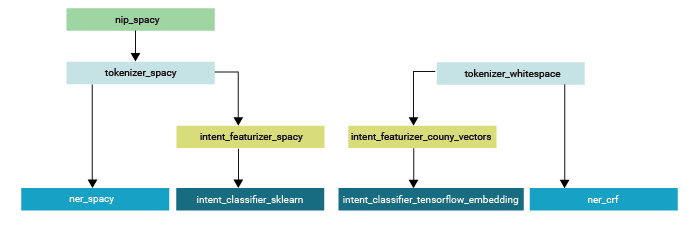
- Pipeline is a series of steps in order to build different processing stages the incoming user messages will have to go through until the model output is produced. Those stages can be tokenization, featurization, intent classification, entity extraction, pattern matching, etc.
- Pipeline dependencies is a way to add any custom components required to build a pipeline. A new custom component can be created to perform a specific task the current framework doesn’t offer.
Below is an example of a pipeline.
Making of a Multilingual Chatbot
The framework can be configured for the language model to use. A default language is configured in the pipeline and will be used as the language model name. The system initializes a specified pre-trained language model. The component applies language model specific tokenization and featurization to compute sequence and sentence level representations for each example in the training data. It includes a language tokenizer and language featurizer etc to utilize the output of this component for next set models in the pipeline.
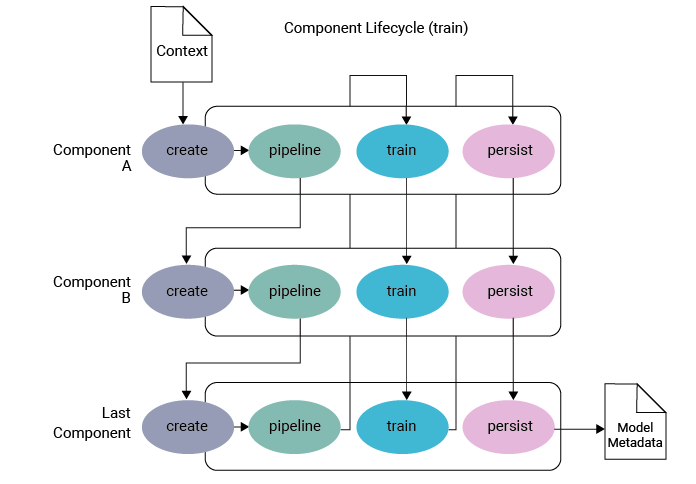
Note that in a language like Arabic it is not possible to use the default approach of split sentences into words as separator. In this case a different tokenizer component can be used. Every component can implement several methods to perform a specific task. In a pipeline these different methods will be called in a specific order.
When there is no training data, the classifier trains word embeddings from scratch, it needs more training data than the classifier which uses pretrained embeddings to generalize well. However, as it is trained on your training data, it adapts to the domain specific messages as there are e.g. no missing word embeddings. Also it is inherently language independent and you are not reliant on good word embeddings for a certain language. Another great feature of this classifier is that it supports messages with multiple intents as described above. In general this makes it a very flexible classifier for advanced use cases.
Brief history of Arabic Language
The Arabic language is a Semitic language that originated in the period between the seventh century BC and the third century AD in the Middle East region.
Arabic is the official language for 22 countries across the globe and spoken by more than 400 million speakers. It is recognized as the 4th most used language of the Internet.
Arabic is classified in three main varieties
- Classical Arabic – a form of Arabic language used in literary texts and Quran
- Modern standard Arabic – used for writing as well as formal conversations
- Arabic dialect – used in daily life communication, informal exchanges
Arabic dialect are mostly divided into six main groups:
- Egyptian
- Levantine
- Gulf
- Iraqi
- Maghrebi
- Others dialects
Arabic speakers on social media, discussion forums and other messaging platforms often use a non standard romanization called ‘Arabizi’ (Arabic plus English) or Arabglizi is the informal Arabic chat alphabet which became a popular phenomenon among younger generations with the introduction of technology between the mid-1990s to early 2000s.
Due to the complexity of this language and the number of corresponding challenges for natural language processing, we have explored multiple approaches to solve this problem.
Challenges in building Arabic Chatbot
We found that there was not much work done on Arabic chatbot and there are more challenges compared to other western languages.
We explored the challenges of creating an Arabic conversational agent that aims to simulate a real conversation with Arabic speaking people. Following are some of the major challenges found when building a conversation chatbot supporting Arabic language.
– Multiple Dialects
Arabic consists of a number of variants that are quite different from each other. The standard arabic is the official written and read language. While the standard arabic language has official standard orthography and a relatively large number of resources, the various Arabic dialects have no standards.
Dialects are not recognized as languages and not taught in schools in the Arab World. However, dialectal Arabic is commonly used in online chatting. So, it is more appropriate to focus on dialectal Arabic in the context of a chatbot.
– Gender-specific terms
English uses gender neutral terms. However, many morphologically rich languages need to use different gender-specific terms in both written and spoken language. For example, am-a-teacher/ I-am-a-nurse may be treated without any gender-specific terms, but many morphologically rich languages need to use different grammatically gender-specific terms for these two expressions.
– Ambiguity and Inconsistency
Arabic orthography represents short vowels and consonantal doubling using optional diacritical marks, which most commonly are not included in the text. This results in a high rate of ambiguity.
Furthermore, Written arabic used by common people may have common mistakes in spellings. The issue of orthography is exacerbated for Arabic dialects where no standard orthographies exist
– Morphological Richness
Arabic words are inflected for a large number of features such as gender, number, person, voices, aspect, etc., as well as accepting a number of attached clitics. In the context of a chatbot system this proves very challenging.
Verbs, adjectives, and pronouns are all gender specific, which requires the chatbot to have two different systems of responses – one for male users and another for female users.
– Idiomatic Dialogue Expressions
As with any other language, Arabic has its own set of unique idiomatic dialogue expressions. One common class of such expressions is the modified echo greeting responses, e.g., while the English greeting ‘Good Morning’ gets an echo response of ‘Good Morning’, the equivalent Arabic greeting. ’Morning of Goodness’ gets a modified echo response of ‘Morning of Light’. Because of all these challenges, an Arabic-speaking chatbot requires its unique databases, as opposed to a machine translation wrapper around an existing English-speaking chatbot.
The Proposed Solution for Arabic NLP
While building the solution for a type of Arabic language or an Arabic dialect, the problem of Arabic NLP is classified into different categories.
Analysing and interpreting a type of Arabic language and dialect is involved to create a set of Orthographic rules, standards and conventions.
A common set of guidelines with specific set of conventions will be helpful in building a customised solution for a dialect.
The process of reading and understanding Arabic is complex. The process involves a pipeline of tasks. The idea is to break the problem into smaller tasks and use machine learning to solve each of the problems. These tasks chaining together and each task that feed into each other will solve the complex problem of understanding Arabic language.
Building NLP pipeline consists of different tasks involved.
– Arabic Language or Dialect analysis
– Building Arabic language or dialect resources
– Language Identification and detection of dialect
– Semantic level analysis
– Arabic Language or Dialect analysis
The first step in the pipeline is to break the text apart into separate sentences. We have tested different available methods to perform the segmentation including Farasa, MADAMIRA and the Stanford Arabic Segmenter. We chose Farasa for this task because of few advantages.
Among these segmentation tools, Farasa outperformed the other two tools in terms of information retrieval. Farasa segmentation/tokenization module is based on SVM-rank using linear kernels that uses a variety of features and lexicons to rank possible segmentations of a word. The features include: likelihoods of stems, prefixes, suffixes, their combinations; presence in lexicons containing valid stems or named entities; and underlying stem templates.
Farasa doesn’t provide few tasks required and MADAMIRA comes handy in feature modelling, tokenization, phrase chunking and named entity recognition.
While we are working on these options, we are also considering Arabert. It is an Arabic pretrained language model based on Google’s BERT architecture.
Additionally, we considered using an additional tool for stop-words which contains 750 arbic stop-words.
To remove prefixes and suffixes, Arabic light stemmer, ARLSTem can be used.
To address gender specific answers, a name to gender map is created to determine the user’s gender, to understand the sentences and provide gender-inflected responses. If the name is not found in the corpus, does not recognize the user’s name, system asks for that information from the user instead.
– Building Arabic language or dialect resources
There are three different major corpus resources available and being tested for the Arabic Chatbot are the following.
The major source considered is TALAA corpus, It is a large Arabic corpus, containing 14 million words. It is built from more than 50K articles from daily Arabic newspaper websites.
We also considered The United Nations Parallel Corpus. It is composed of official records and other parliamentary documents of the United Nations that are in the public domain. This corpus is available in the six official languages of the United Nations including Arabic. The current version of the corpus contains content that was produced and manually translated between 1990 and 2014, including sentence-level alignments.
Arabert’s model is trained on ~70M sentences or ~23GB of Arabic text with ~3B words. The training corpora are a collection of publicly available large scale raw arabic text Arabic Wikidumps, The 1.5B words Arabic Corpus.
– Language Identification and detection of dialect
There are different approaches used for dialect identification in case of identifying multi dialects in Arabic languages. For the classification task, we considered using Naive Bayes and SVM algorithms.
We relied on two different approaches:
(1) rule-based and
(2) statistical-based (using several machine learning classifiers).
However the statistical approach outperforms the rule-based approach where the SVM classifier is more accurate than other statistical classifiers.
We considered a tool for dialect identification that automatically identifies the dialect of a particular segment of speech or text of any size. This task built several classification systems and explored a large space of features. The results show that we can identify the exact city of a speaker at an accuracy of 67.9% for sentences with an average length of 7 words and reach more than 90% when we consider 16 words.
In case of multi level dialect identification model, dialect identification task uses a Multinomial Naive Bayes (MNB) classifier for the learning task. MNB is a variation of Naive Bayes that estimates the conditional probability of a token given its class as the relative frequency of the token t in all documents belonging to class c. MNB has proven to be suitable for classification tasks with discrete features.
– Semantic level analysis
The task on which most work has been conducted in this is Sentiment Analysis.
In the context of Sentiment analysis, We started with a simple sentiment analysis task using the bag of words model, with unigram and bi-gram TF-IDF weights. As a classifier, Naive Bayes algorithm is used in combination with the constructed lexicon and achieved F1-score up to 79%.
We also considered Ar-embeddings and arabic-sentiment-analysis tools for Sentiment analysis. Both of these tools are evaluated with a set of Arabic lanaguage tweets using word2vec.
Conclusion and Perspectives
Based on research and experience with building an Arabic Chatbot, there are various available tools and resources on Arabic NLP and selection of right tool and customization of the tool as per the use-case will improve the accuracy of conversational chatbot significantly.
Recently there is more work being done on Arabizi and MSA as they are widely used on the Internet. The framework that handles dialects/regions individually can give better results compared to a single solution for all Arabic dialects. The deep learning approach will be more efficient than traditional approaches like SVM and NB or Arabic language processing.
By leveraging the power of Arabic NLP and AI technologies, a customised NLP solution for Arabic language will increase the accuracy by 20%-30% than the existing chatbots in the market.